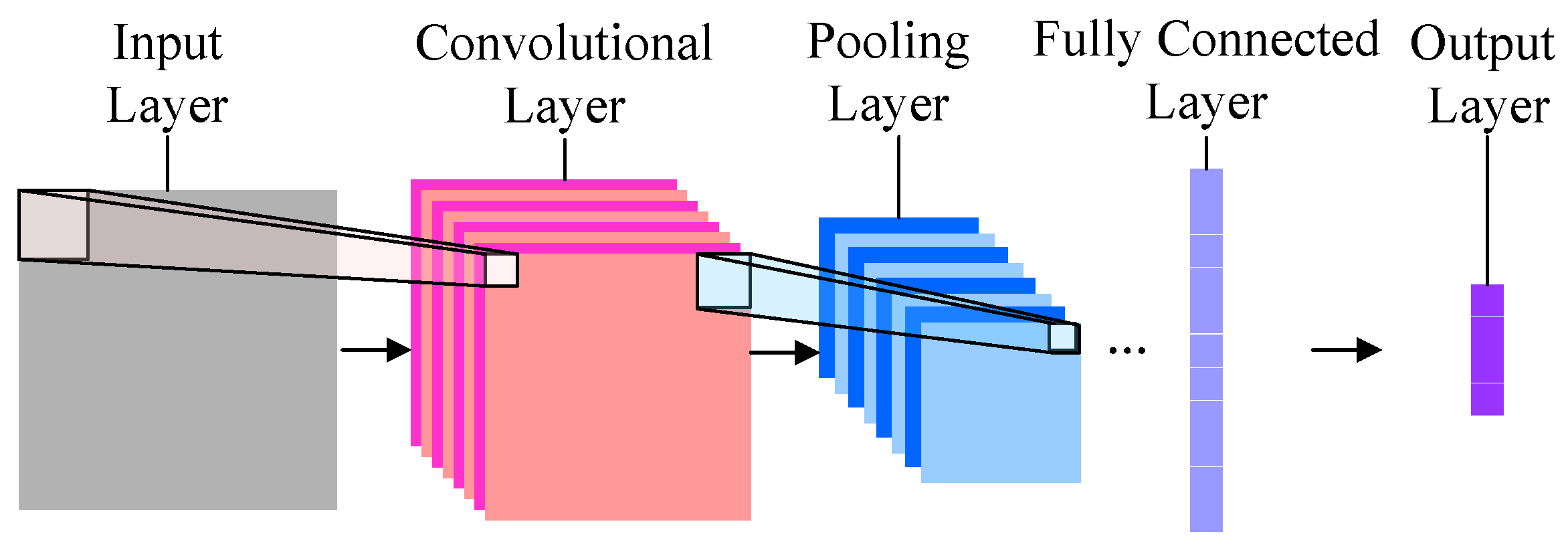
Using CNN's for multiple object classification
CNN's are very good at image classification but a lot of medical image analysis does not require classifying a single image but objects or regions of an image in order to show highlight lesions.
There has been a lot of research into how best to do this and the first major paper on it was called R-CNN.
CNNs have traditionally been used for image classification, however, in 2014 a paper4 on object detection using CNNs described a technique which enabled CNNs to be used to accurately isolate objects in images. The architecture was titled R-CNN (Regions with CNNs)5.
R-CNN
R-CNN uses a process called selective search to create regions of different sizes it wishes to check for objects.
After creating the propositions, R-CNN makes the region square by warping it and then runs it through a modified version of AlexNet to determine if it is a valid region and then adds a SVM that does the classification.
Finally, R-CNN will try to improve the bounding boxes using linear regression.
There are 2 main reasons why R-CNN can be slow:
- Every region proposal has to be passed through the CNN to determine if it is valid
- There are 3 models which need training (CNN for features, classifier and regression model)
2015 saw the author of R-CNN release a new paper on an architecture called Fast R-CNN which improved on R-CNN and solved both of the problems above.
How did he achieve this?
Solving the first issue involved making a single pass through the CNN of the image and then using obtaining features for a region by selecting a region on the CNNs feature map, reducing the number of passes to one.
Solving the second issue meant jointly training the CNN, classifier and regressor in a single model. Now only one network is used as you can see from the image above.
In 2016 an improvement in the regional proposals are made lead to Faster R-CNN. In 2017 Mask R-CNN improved on this and enabled object segmentation and classification.