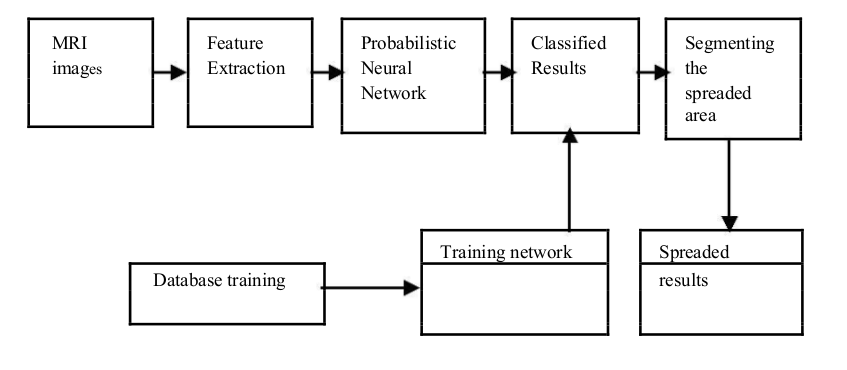
The network then passes data from the RB layer to the summation layer which calculates the closest distance between the training images, and the input image and classifies the image based on the closeness of the data. This is usually done using Bayesian Theory . Some of the sources show the summation layer performing the following calculations
The PNN separates the input vectors into classes. An input vector is classified into a class \(A\) by the equation:
$$ P_A C_A F(x)_A > P_B C_B F(x)_B $$
Where
\(P_A\) - Priori probability of occurrence of patterns in class
\(C_A\) - Cost associated with classifying vectors
\(F(x)_A\) - Probability density function of class A
given by the equation $$ F(x)_A = \frac{1}{(2π)^{\frac{n}{2}} \ \sigma^n \ m_n} $$
with $$\sum_{i = 1}^m exp[-2 \ \frac{(x - x_A)^r (x - x_{Ai})}{\sigma^2}]$$
Where
\(x_{Ai}\) - i
th training pattern from class A
\(n\) - Dimension of the input vectors
\(\sigma\) - Smoothing parameter (corresponds to standard deviation of gaussian distribution)
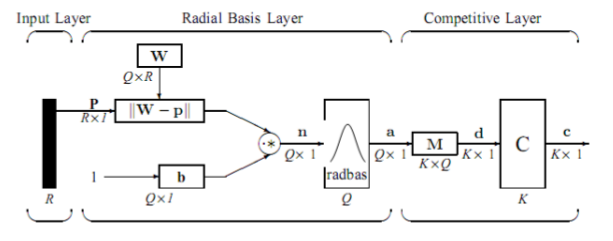
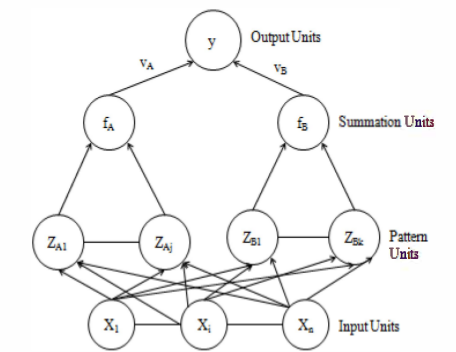
The Mathematical representation of a PNN as a structural diagram.